Recent Update
Preprint
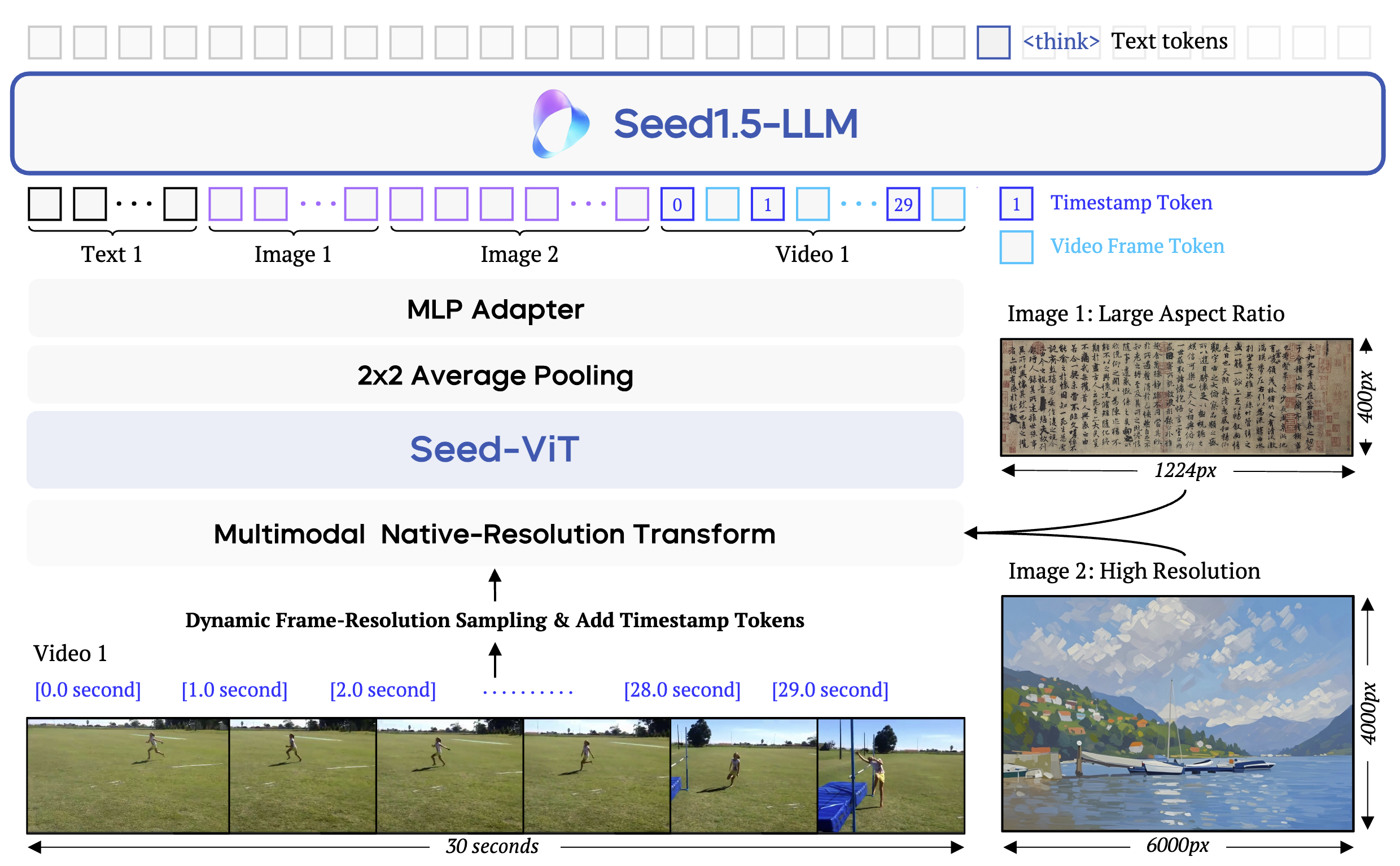 |
Seed1.5-VL Technical ReportCore Contributor in Seed1.5-VL TeamarXiv Preprint, 2025 [paper] [code] [homepage] |
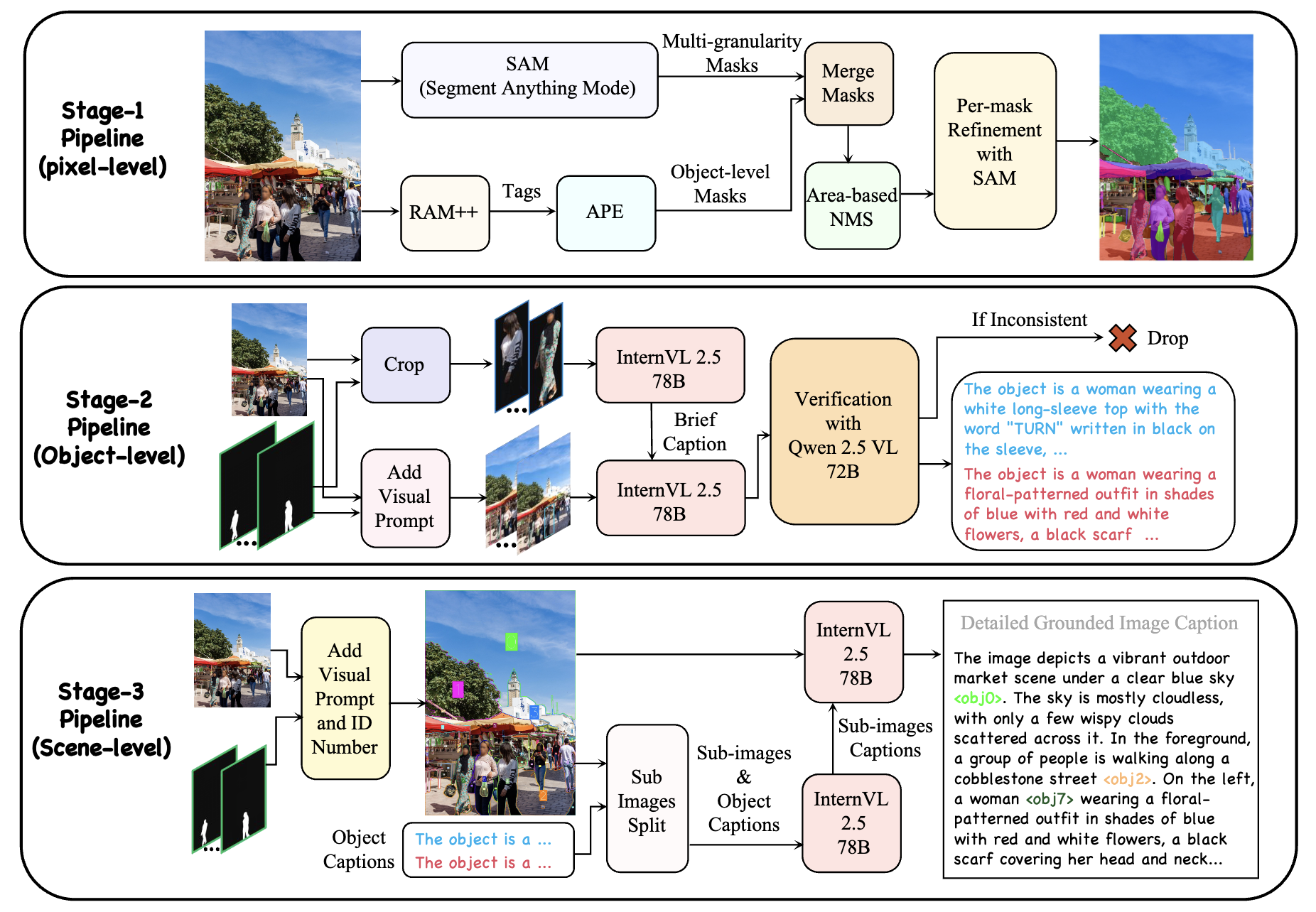 |
DenseWorld-1M: Towards Detailed Dense Grounded Caption in the Real WorldXiangtai Li*, Tao Zhang*, Yanwei Li*, Haobo Yuan, Shihao Chen, Yikang Zhou, et.al.arXiv Preprint, 2025 [paper] [code] |
Journal Paper
 |
Mini-Gemini: Mining the Potential of Multi-modality Vision Language ModelsYanwei Li*, Yuechen Zhang*, Chengyao Wang*, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, Jiaya JiaIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 [paper] [code] [project] |
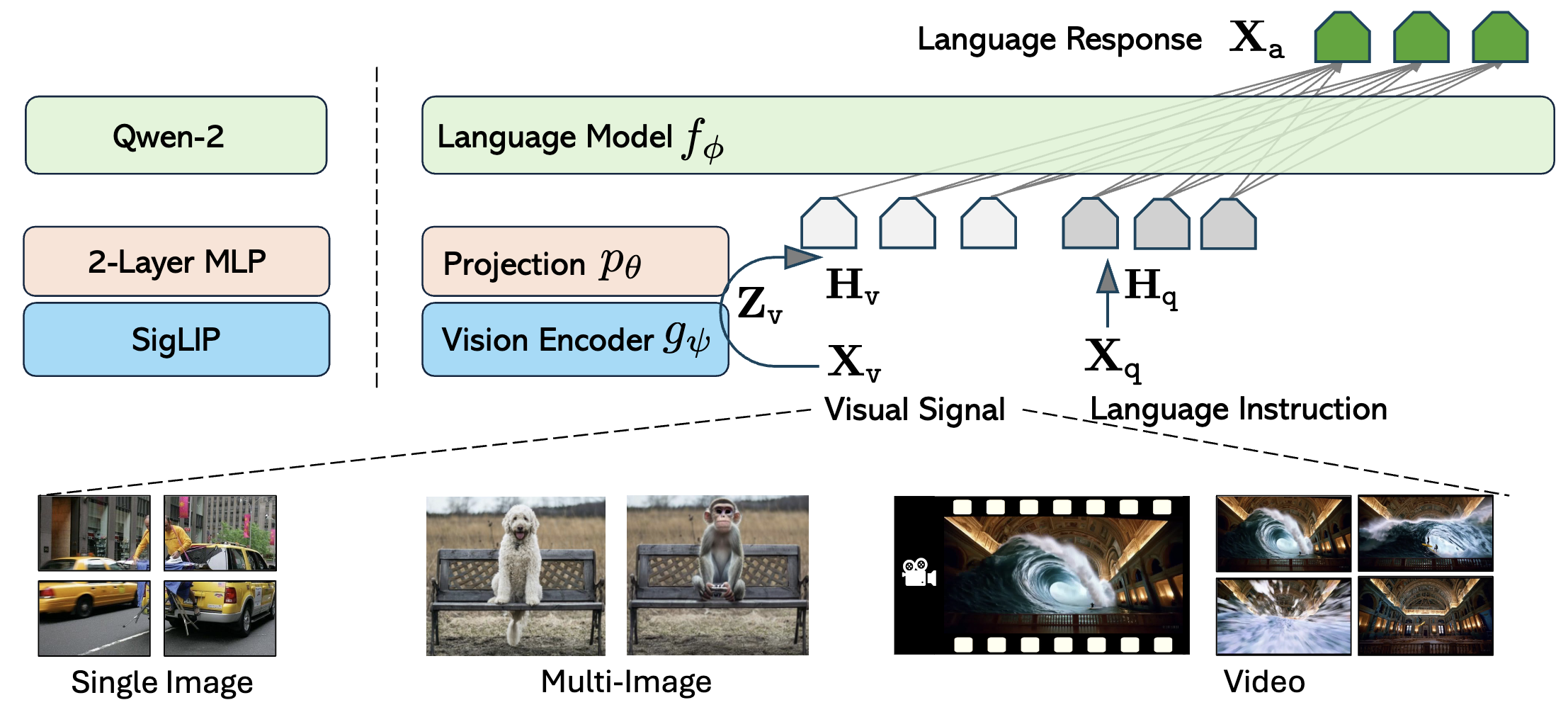 |
LLaVA-OneVision: Easy Visual Task TransferBo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, Chunyuan LiTransactions on Machine Learning Research (TMLR), 2025 [paper] [code] [project] |
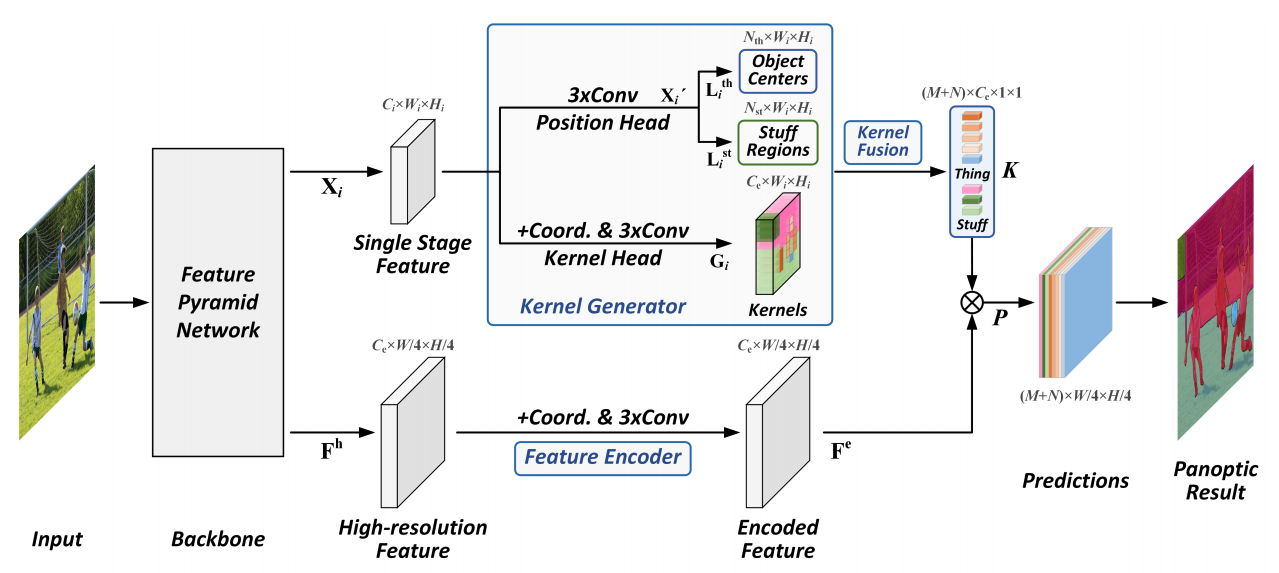 |
Fully Convolutional Networks for Panoptic Segmentation with Point-based SupervisionYanwei Li, Hengshuang Zhao, Xiaojuan Qi, Yukang Chen, Lu Qi, Liwei Wang, Zeming Li, Jian Sun, Jiaya JiaIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022 [paper] [code] |
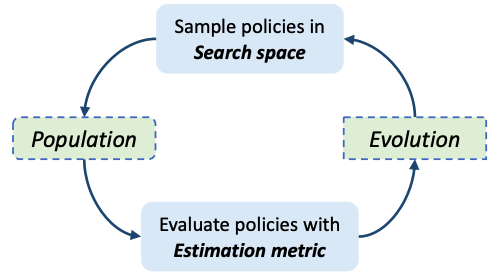 |
Scale-aware Automatic Augmentations for Object Detection with Dynamic TrainingYukang Chen, Peizhen Zhang, Tao Kong, Yanwei Li, Xiangyu Zhang, Lu Qi, Jian Sun, Jiaya JiaIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022 [paper] |
Conference Paper
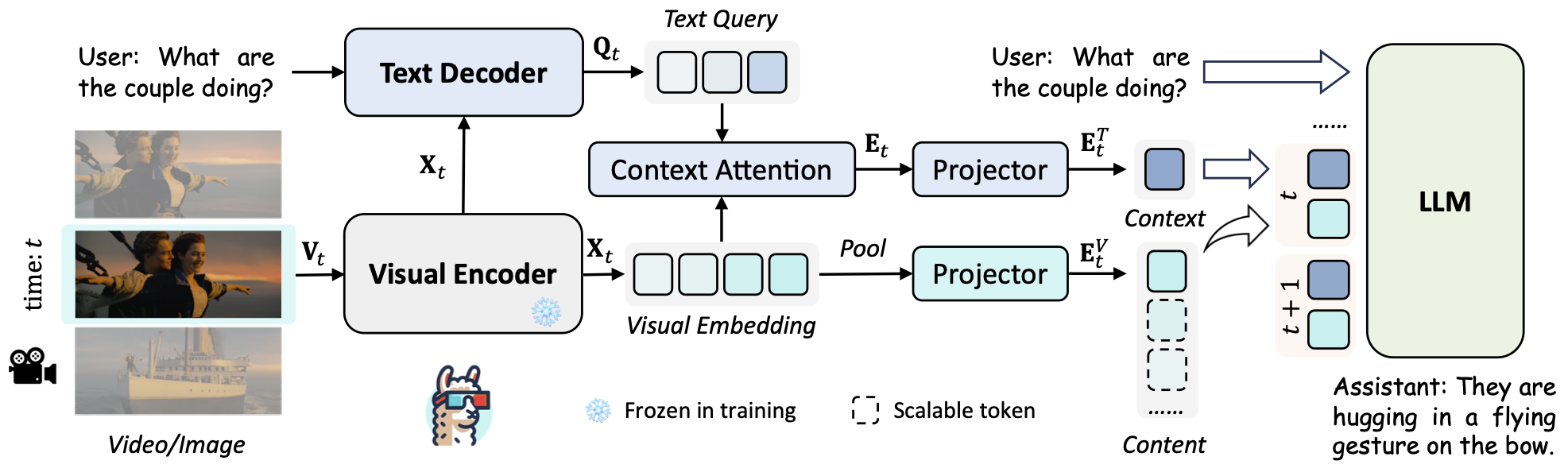 |
LLaMA-VID: An Image is Worth 2 Tokens in Large Language ModelsYanwei Li*, Chengyao Wang*, Jiaya JiaEuropean Conference on Computer Vision (ECCV), 2024 [paper] [code] [project] |
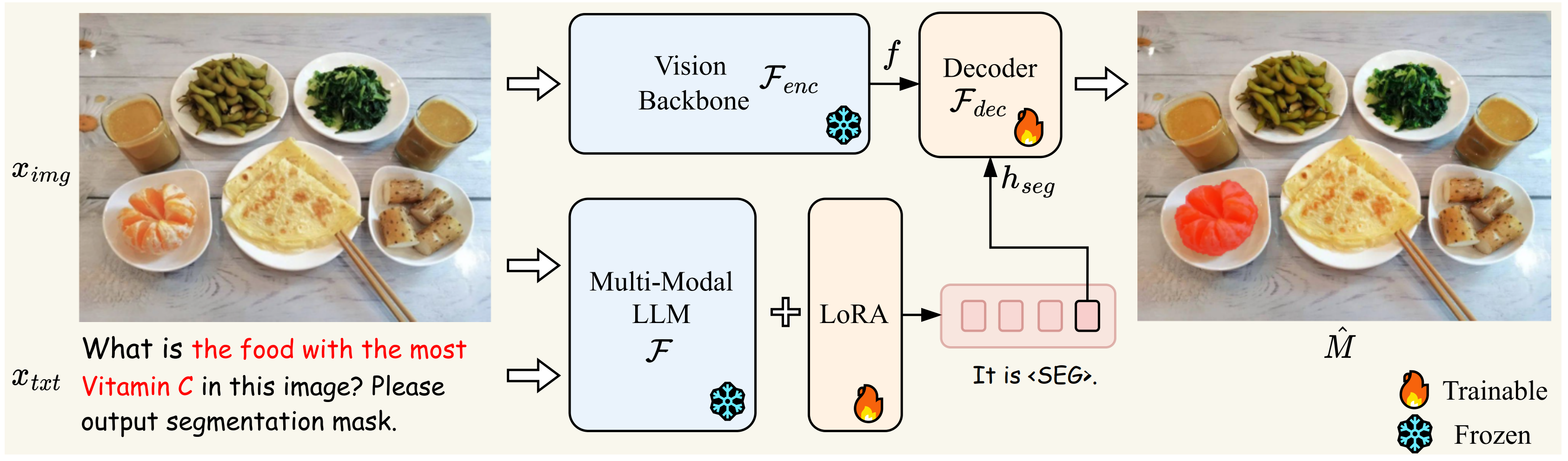 |
LISA: Reasoning Segmentation via Large Language ModelXin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya JiaIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 (Oral) [paper] [code] |
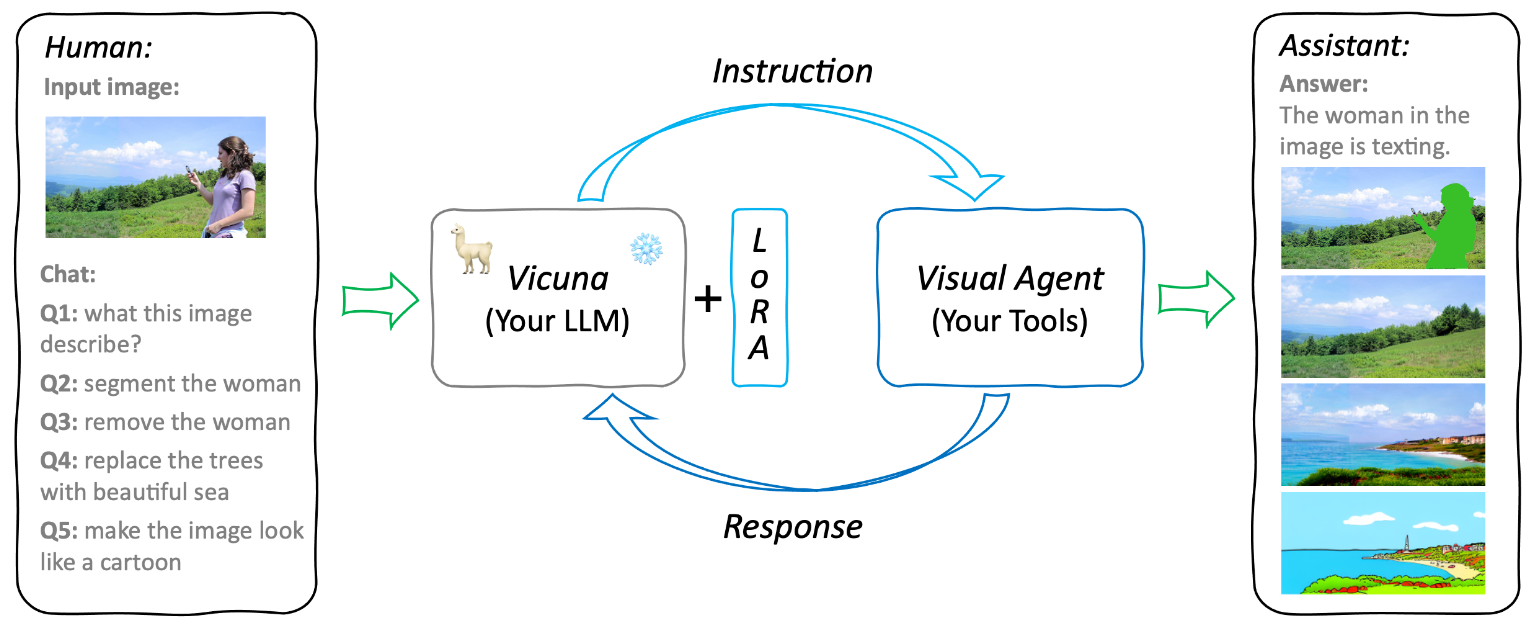 |
GPT4Tools: Teaching Large Language Model to Use Tools via Self-instructionRui Yang*, Lin Song*, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, Ying ShanAdvances in Neural Information Processing Systems (NeurIPS), 2023 [paper] [code] |
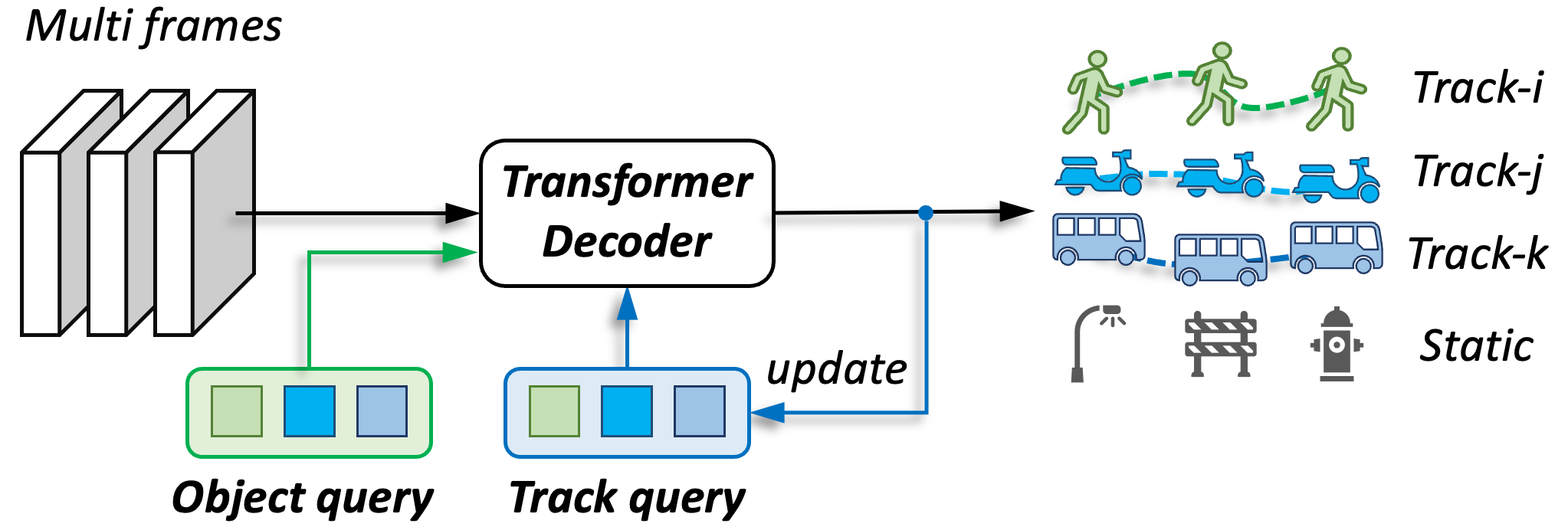 |
End-to-end 3D Tracking with Decoupled QueriesYanwei Li, Zhiding Yu, Jonah Philion, Animashree Anandkumar, Sanja Fidler, Jiaya Jia, Jose AlvarezInternational Conference on Computer Vision (ICCV), 2023 [paper] [code] |
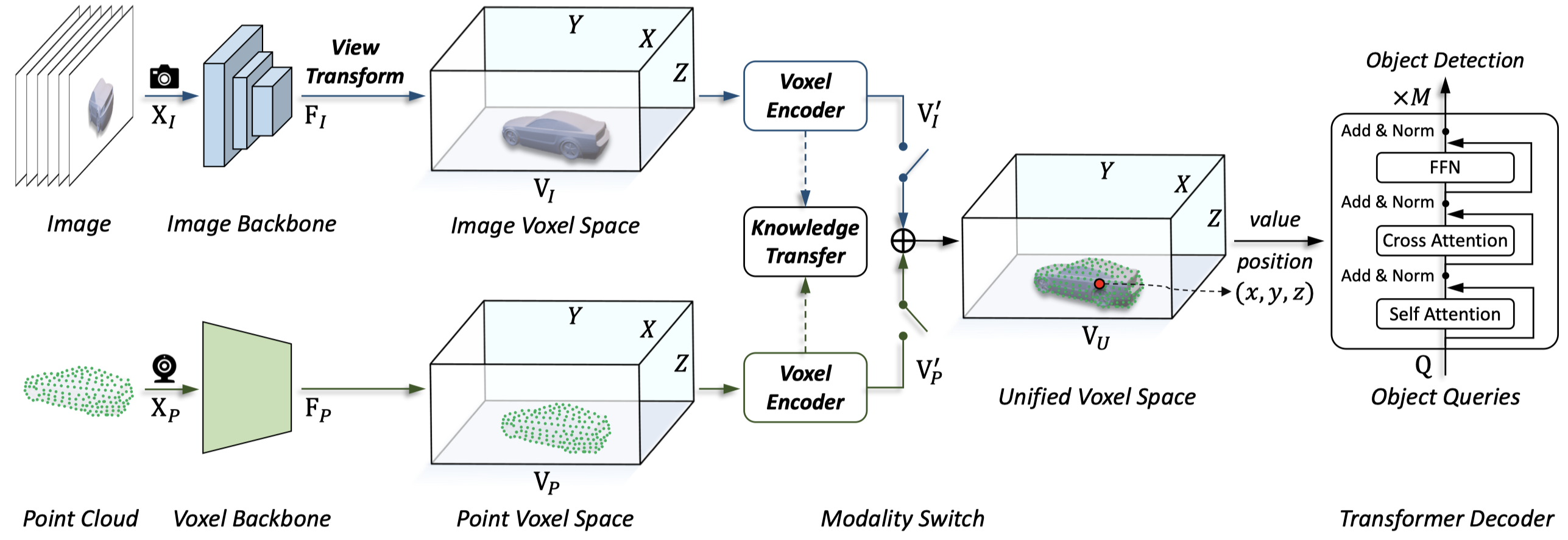 |
Unifying Voxel-based Representation with Transformer for 3D Object DetectionYanwei Li, Yilun Chen, Xiaojuan Qi, Zeming Li, Jian Sun, Jiaya JiaAdvances in Neural Information Processing Systems (NeurIPS), 2022 [paper] [code] |
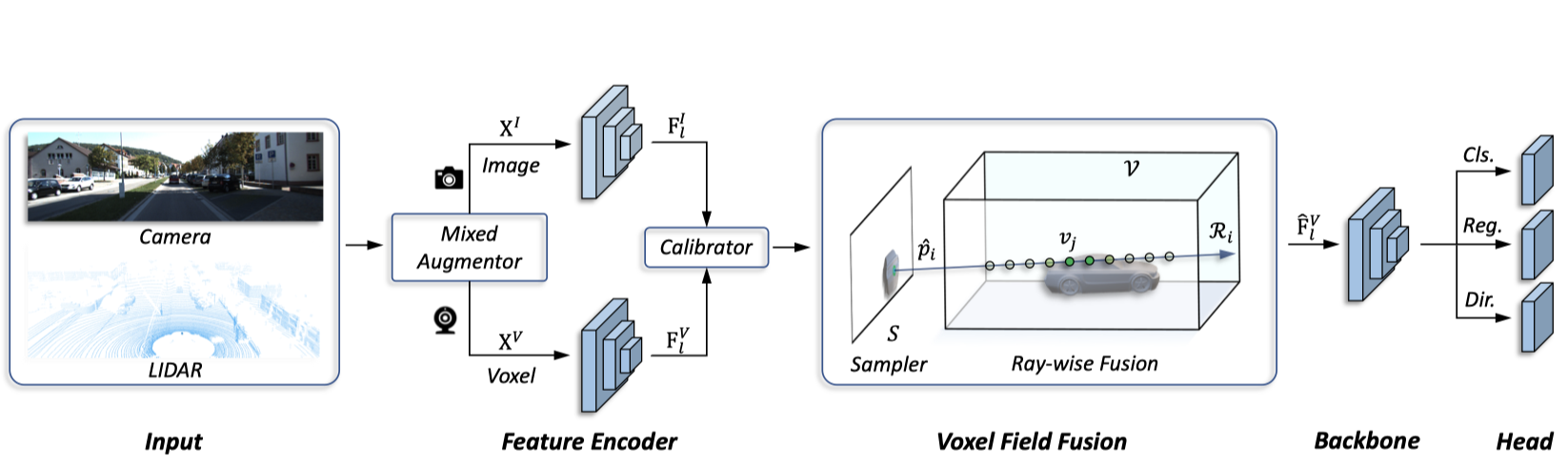 |
Voxel Field Fusion for 3D Object DetectionYanwei Li, Xiaojuan Qi, Yukang Chen, Liwei Wang, Zeming Li, Jian Sun, Jiaya JiaIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [paper] [code] |
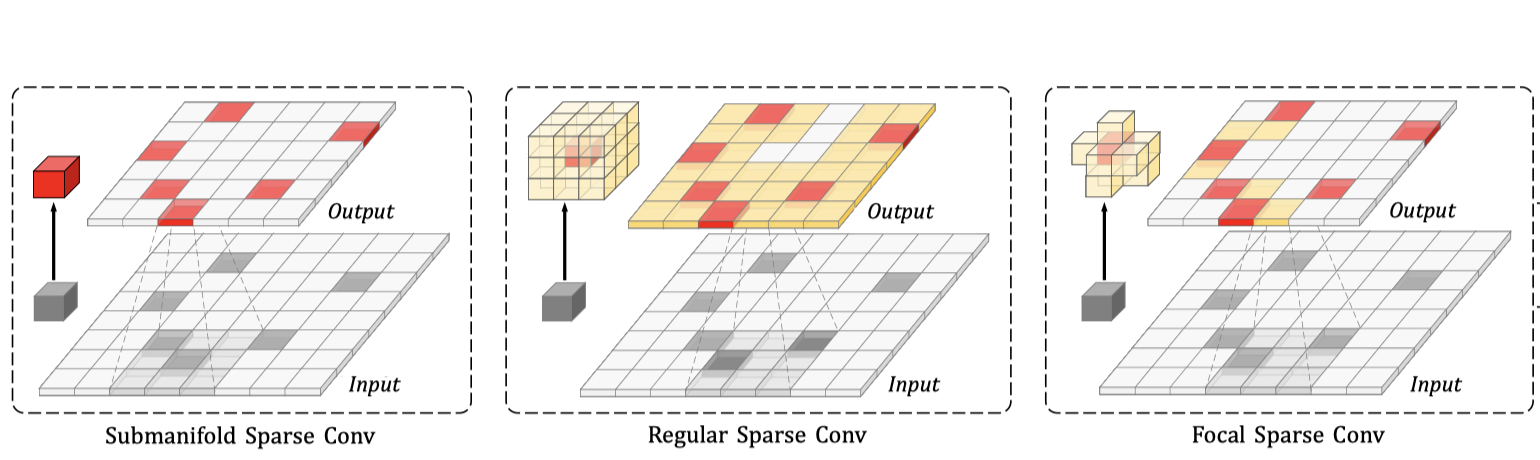 |
Focal Sparse Convolutional Networks for 3D Object DetectionYukang Chen, Yanwei Li, Xiangyu Zhang, Jian Sun, Jiaya JiaIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Oral) [paper] [code] |
|
Fully Convolutional Networks for Panoptic SegmentationYanwei Li, Hengshuang Zhao, Xiaojuan Qi, Liwei Wang, Zeming Li, Jian Sun, Jiaya JiaIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (Oral) [paper] [code] [slides] |
|
Scale-aware Automatic Augmentation for Object DetectionYukang Chen*, Yanwei Li*, Tao Kong, Lu Qi, Ruihang Chu, Lei Li, Jiaya JiaIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [paper] [code] |
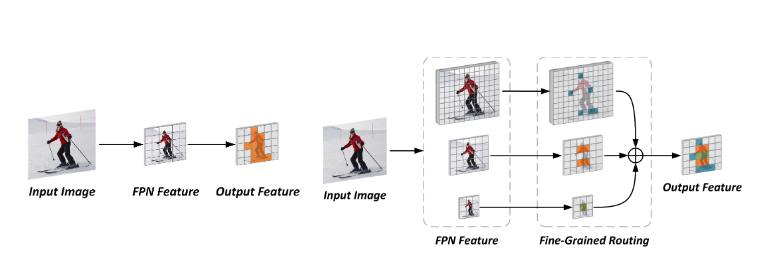 |
Fine-Grained Dynamic Head for Object DetectionLin Song, Yanwei Li, Zhengkai Jiang, Zeming Li, Hongbin Sun, Jian Sun, Nanning ZhengAdvances in Neural Information Processing Systems (NeurIPS), 2020 [paper] [code] |
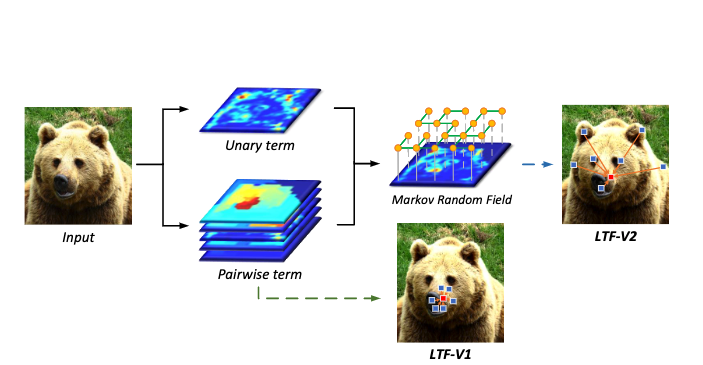 |
Rethinking Learnable Tree Filter for Generic Feature TransformLin Song, Yanwei Li, Zhengkai Jiang, Zeming Li, Xiangyu Zhang, Hongbin Sun, Jian Sun, Nanning ZhengAdvances in Neural Information Processing Systems (NeurIPS), 2020 [paper] [code] |
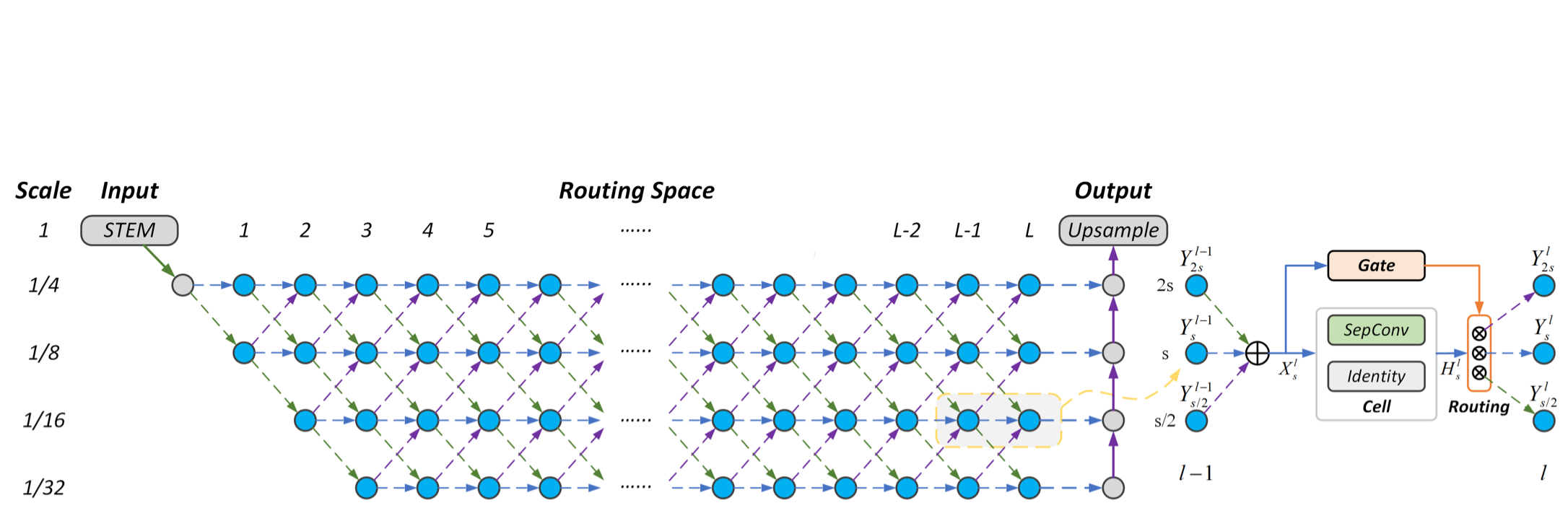 |
Learning Dynamic Routing for Semantic SegmentationYanwei Li, Lin Song, Yukang Chen, Zeming Li, Xiangyu Zhang, Xingang Wang, Jian SunIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020 (Oral) [paper] [code] [video] [slides] |
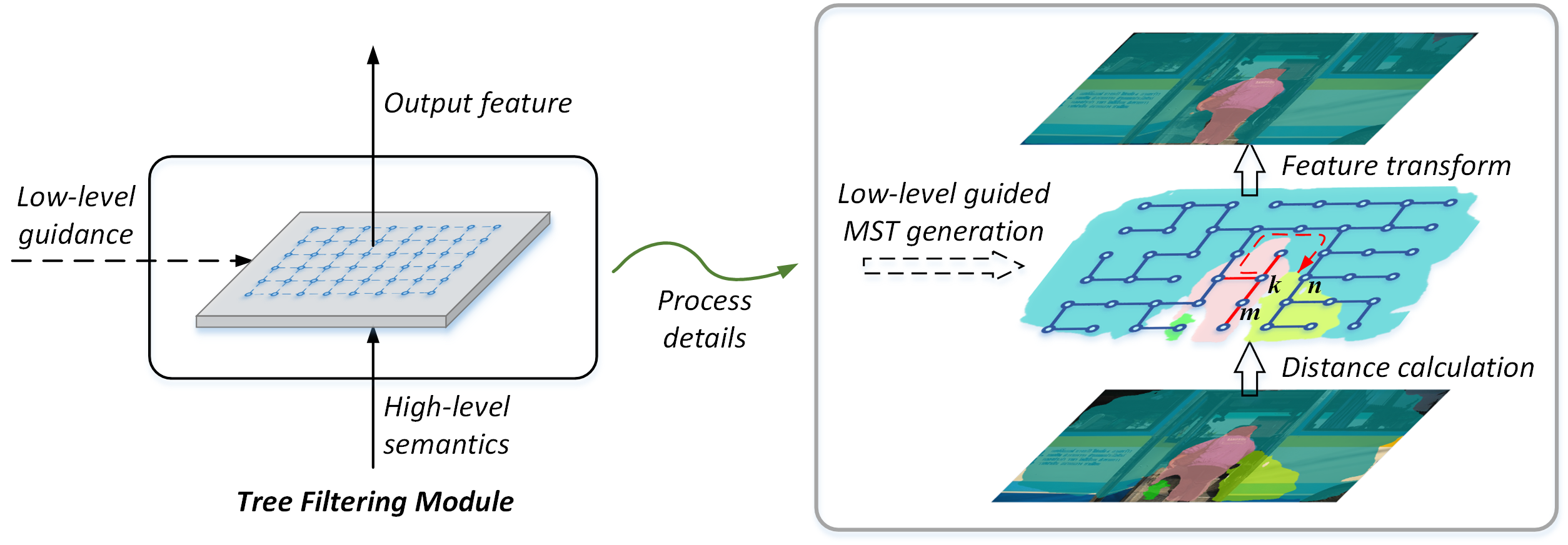 |
Learnable Tree Filter for Structure-preserving Feature TransformLin Song*, Yanwei Li*, Zeming Li, Gang Yu, Hongbin Sun, Jian Sun, Nanning ZhengAdvances in Neural Information Processing Systems (NeurIPS), 2019 [paper] [code] |
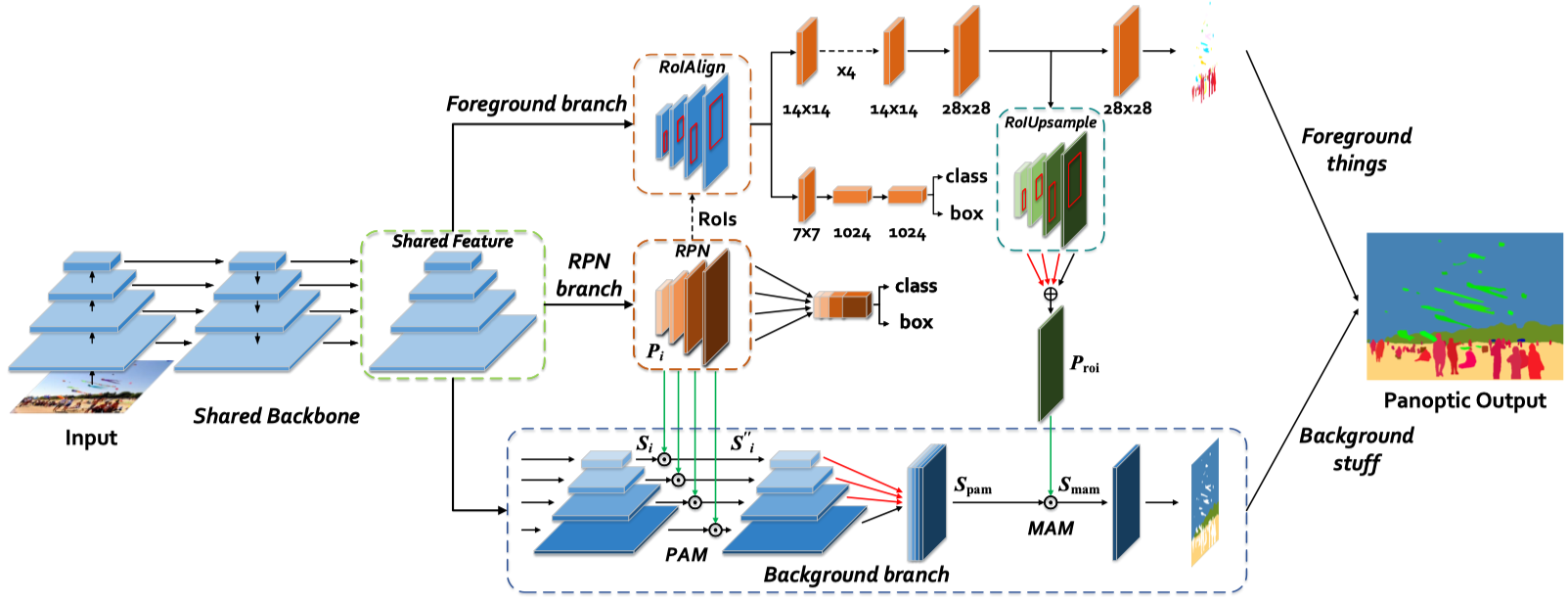 |
Attention-guided unified network for panoptic segmentationYanwei Li, Xinze Chen, Zheng Zhu, Lingxi Xie, Guan Huang, Dalong Du, Xingang WangIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019 [paper] |
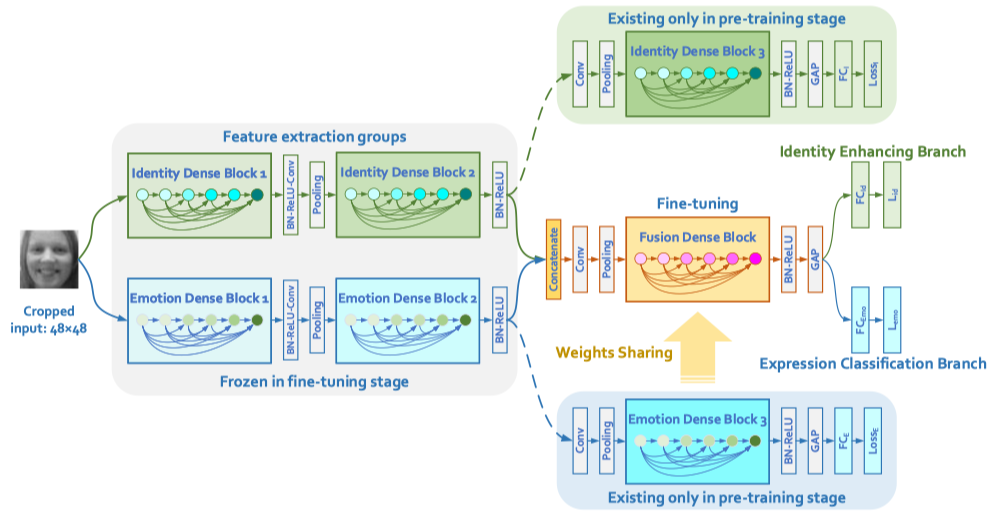 |
Identity-Enhanced Network for Facial Expression RecognitionYanwei Li, Xingang Wang, Shilei Zhang, Lingxi Xie, Wenqi Wu, Hongyuan Yu, Zheng ZhuAsian Conference on Computer Vision (ACCV), 2018 [paper] |
Workshop & Competition
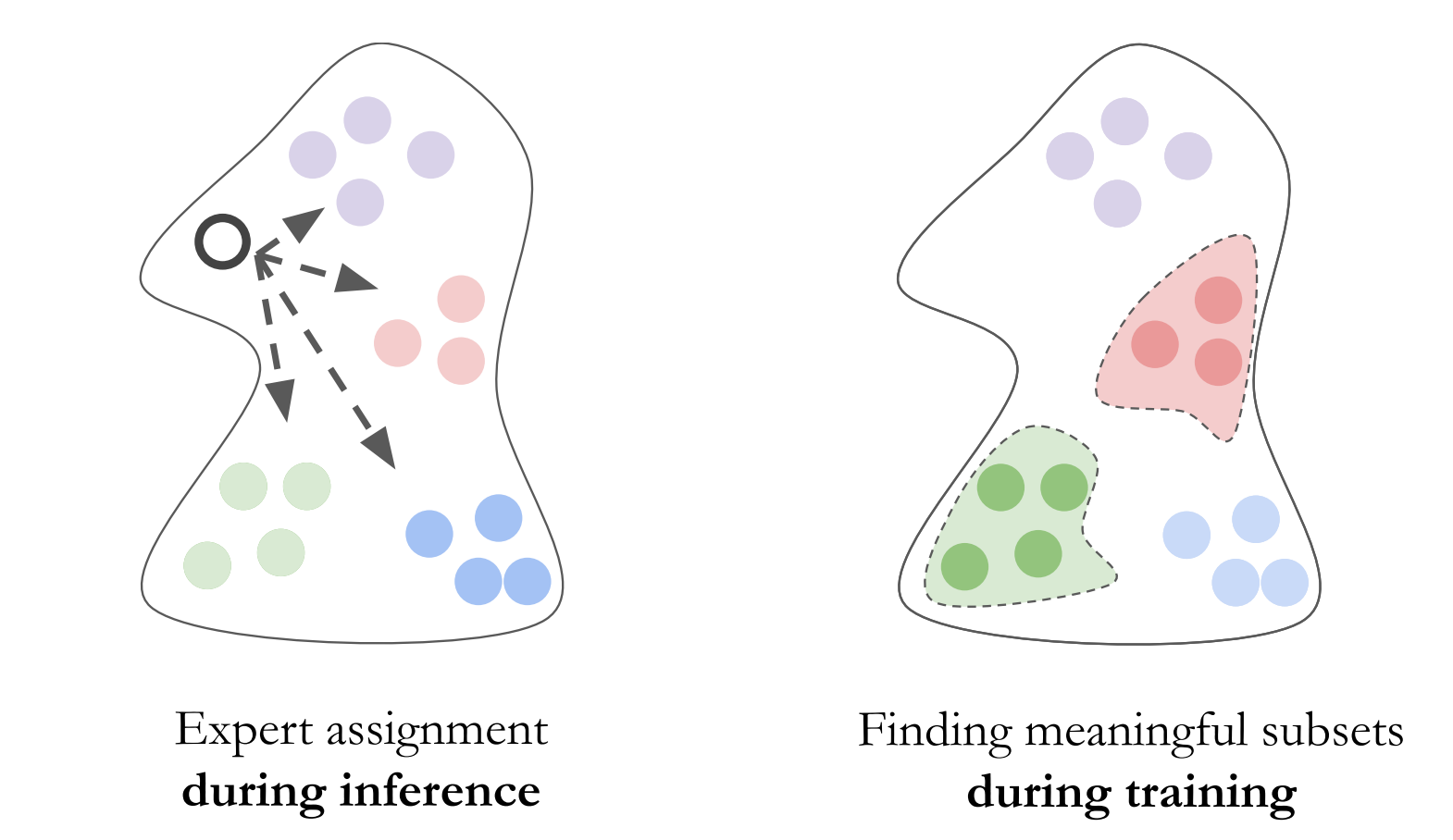 |
Diversified Dynamic Routing for Vision TasksBotos Csaba, Adel Bibi, Yanwei Li, Philip Torr, Ser-Nam LimEuropean Conference on Computer Vision (ECCV) Workshop, 2022 [paper] |
 |
MicroSoft COCO Panoptic ChallengeYanwei Li*, Naiyu Gao*, Chaoxu Guo, Xinze Chen, Qian Zhang, Guan Huang, Xin Zhao, Kaiqi Huang, Dalong Du, Chang HuangWin 2nd place, Oral in ECCV COCO Workshop, 2018. [slides] |
 |
State-aware Re-identification Feature for Multi-target Multi-camera TrackingPeng Li* , Jiabin Zhang* , Zheng Zhu*, Yanwei Li, Lu Jiang, Guan HuangIEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshop, 2019 [paper] |